
What is Hadoop? Why do I need to know about it?
Suppose your company collects a lot of data—not just gigabytes but terabytes or petabytes. To make that data useful, you need a system to store all that data reliably and retrieve and manipulate it quickly. Hadoop is a distributed architecture and infrastructure for storing and processing “Big Data.” If your company deals with Big Data, your CTO will be talking about Hadoop implementations.
Who invented Hadoop and why?
As Internet data began to proliferate, outstripping the capabilities of single servers, search engine companies needed a cost-effective, distributed system that would run on commodity computers. Incorporating two key ideas from Google—the Google File System and an engine called MapReduce—engineers from Yahoo created the first versions of Hadoop. Ultimately, Yahoo open-sourced Hadoop as part of the Apache Software Foundation.
What kinds of problems was it designed to solve?
Hadoop was designed to confer two key benefits.
- First, it can reliably store massive and/or numerous files—too large or too many to fit on a single server—by using multiple computers.
- Second, it can take any problem that can be broken down into small, identical steps, and run those steps on multiple machines in parallel.
Here are two case examples of Hadoop in action:
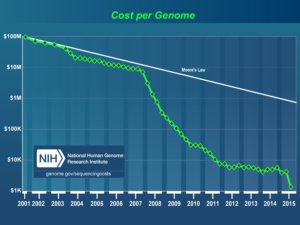
Genome processing and DNA sequencing: Hadoop helped the National Human Genome Research Institute reduce the cost of sequencing one human genome by 99% compared to using standard technology. The process generates about 100GB of compressed data.
Energy metering and usage management: Advanced metering technologies such as smart meters and thermostats generate more data than utilities can process. Utility service provider Opower uses Hadoop to combine that data with demographic, weather and consumer data to provide energy usage information directly to consumers, who have used it to save 2.7 terawatt hours and more than $500 million to date.

What are the challenges of building a system like this?
Mainly, reliability and scalability. Suppose the data is distributed across 1,000 computers. With that many nodes subject to faults, the Mean Time Between Failures for the whole system could be less than one day! How do you access the data on that failed node? The system must tolerate frequent faults yet guarantee rapid data availability across a system of vast size.
Who uses Hadoop and for what?
Besides those mentioned earlier, companies like Twitter, Facebook, LinkedIn, eBay, Hulu, the New York Times, and IBM use Hadoop to manage their Big Data applications.
Sears uses Hadoop to analyze marketing campaigns for loyalty club members. China Mobil Guangdong uses it to store and analyze customer call records and billing information. NextBio uses it to process massive amounts of human genome data. Ancestry uses it to search and retrieve more than 47 million family trees, including birth, death, census, military and immigration records.
Why did they call it Hadoop? Why is the mascot an elephant?
Doug Cutting, one of Hadoop’s creators at Yahoo, named Hadoop after his 2-year-old son’s toy elephant. His son is now 13 and (true story) has demanded royalties from the project.
- Where can I learn more about Hadoop?
For the technical basics, return to the Peaxy blog in a couple weeks for the Hadoop Technical Overview. - We recommend these resources for a deeper dive into Hadoop:
An introduction to Apache Hadoop for big data, by Sachin P. Bappalige on opensource.com
Hadoop: What it is and how it works, by Brian Proffitt on readwrite.
The Peaxy Executive Series is designed to explain quickly and simply what business leaders need to know about using big data and data access systems.