Mining For “Crown Jewel” Data Sets: Q&A With Manuel Terranova
September 11, 2017
In the age of Industry 4.0, Big Data and the Internet of Things, manufacturing companies are, for the most part, focused on analyzing and using structured data sets. However, for all the data generated in your company, much of it, including “Crown Jewel Data sets” are trapped in monolithic storage architectures.
What are Crown Jewel Data sets?
Peaxy specializes in mining for trapped, unstructured data sets, liberating the data and facilitating full access to all of your company’s information.
Peaxy works with unstructured data sets — more specifically, the data sets we call “crown-jewel data sets.” The crown jewels include telemetry (test bench data and mission-critical equipment remote monitoring), simulation (structural analysis, computational fluid dynamics and finite element analysis) and geometry (engineering drawings, schematics and 3D models). Peaxy works with these data sets to aggregate the crown jewels and make those data sets readily accessible to the people who need them the most.
This Q&A covers everything from the crown jewels, to the Industrial Internet, to security and how Peaxy helps companies utilize these hidden — but vital — data sets.
Q: What are some obstacles manufacturing companies face when transitioning to Industry 4.0?
Terranova: Data is critical to creating “smart factories”, which is the core of Industry 4.0. Peaxy focuses on data sets that are trapped. This comes from more than 25 years of deploying data in a monolithic way. Similarly, test bench data is often trapped in the test cell. The trick is to liberate the data set, aggregate it together with the “crown-jewel data” sets and use the empirical data coming off the test bench to validate the simulation models that are driving the product design.
I see customers facing the same challenges over and over again — it is really hard to liberate the data sets from the test cell, bring the data back to the engineer who needs it so they can validate the simulation to begin with.
If you’re not able to do that, you might suffer from a dilemma called simulation drift. With simulation drift, the models are validated infrequently. That means the engineers have to add a fudge factor which results in over-engineered, non-competitive products.
This idea of tying the empirical test data and the remote monitoring diagnostics data back to the engineering asset is really essential. I don’t see it as a manufacturing problem, but rather as a product lifecycle management problem.
Q: What are some solutions to this problem?
Terranova: The challenge for companies hoping to remain competitive over the next two or three decades is to efficiently use their unstructured, mission-critical data sets. Those are the data sets that allow you to support predictive maintenance, simulation management and digital twins at enterprise scale.
Our solution aggregates these digital assets and makes them available to a much broader set of stakeholders. It is incredible how often these data sets are unfindable and unsearchable.
It is important to clarify that we don’t work with structured data and advanced supply chain planning. Rather, we solve the unstructured data challenges that exist on the manufacturing shop floor and beyond in engineering and field services.
We use our technology to create an engineering and manufacturing data plane where these assets can be readily shared. Sharing is a much bigger challenge in the unstructured data world than it is for structured data like ERP.
We are also working to provide the ability to search the unstructured data sets for the aggregated data, because traditional search functions don’t work in that construct. The trick is to know when the data sets have intrinsically changed, because re-indexing them every evening will take down the corporate network.
Architectures that are going to help people access the data sets have to be flexible and incremental. At the same time, they need to scale linearly and provide deterministic performance for the next three to four decades.
When you copy unstructured data assets, you move the file-based crown-jewel data sets to refresh the underlying hardware they sit on, and this changes all the path names associated with the files. In this process, the knowledge used to track the assets gets lost, and people can’t find them again.
We provide companies with the ability to put those data sets into a data abstraction layer and protect the asset from the underlying data refresh that puts it into jeopardy every three to five years.
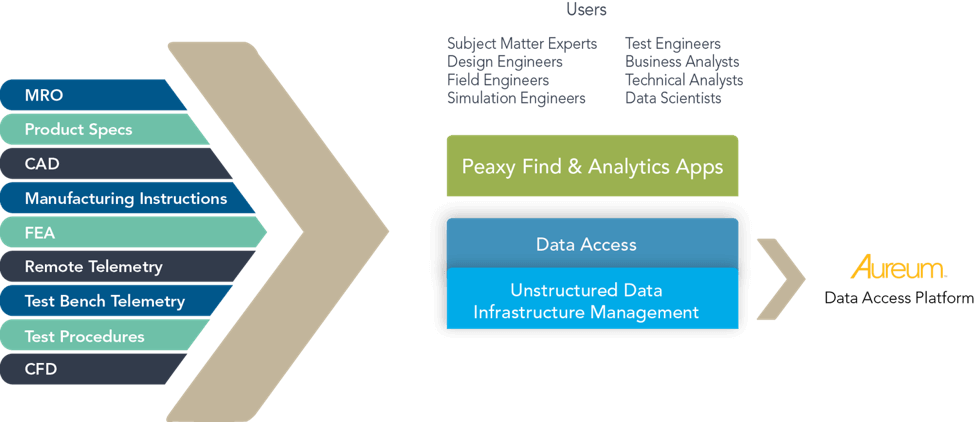
Peaxy Aureum: Unstructured Data Access
Q: Do you ever encounter customers who are concerned with the security of their unstructured data?
Terranova: When data is trapped on data islands, it is pretty secure — just not secure in the ways we want it to be. The systems were designed to limit access to a very small set of individuals in the enterprise. In order to unlock the data sets, we need to honor the permissions and authentication schemata that are in place.
That being said, security cannot be used as a barrier to aggregating and making the data sets more visible and accessible to a broader set of stakeholders. Ultimately, this will lead to a competitiveness issue. Security concerns need to be confronted, because the assets need to be shared in a much better way than they are today.
Security is a domain problem. It is a question of bringing the right people to the table and making sure that when you think about data as an asset, you are also thinking about security on and off the manufacturing campus.
Note: Originally published April 24, 2015 on Manufacturing.Net